Does anyone know if there is a way to download data by county? I am currently hoping to download all the data for each monitor within Sheffield and was wondering what the best way is to do this? I was hoping to find the data classed either by county or even sensor name instead of by date as I would like to download all the data (so all the dates) for each sensor in Sheffield.
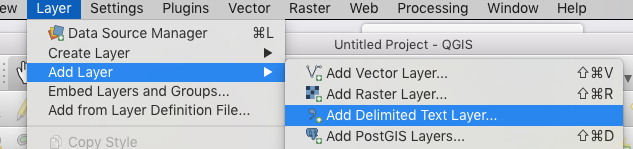
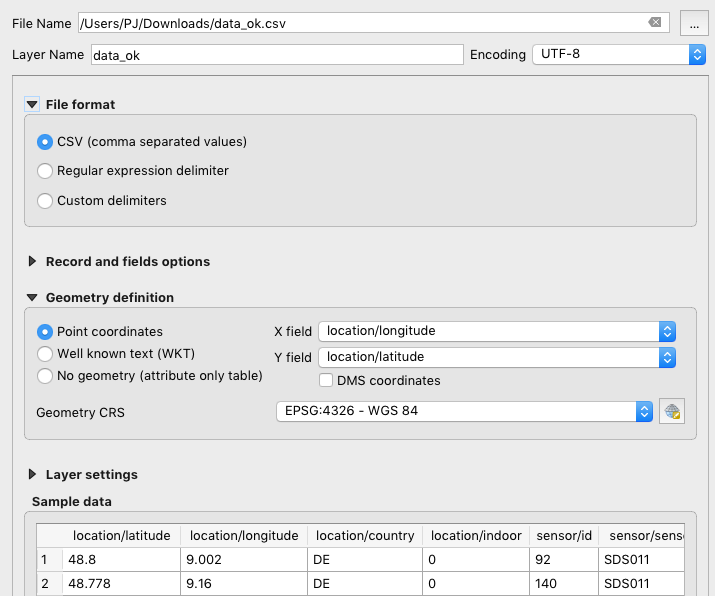
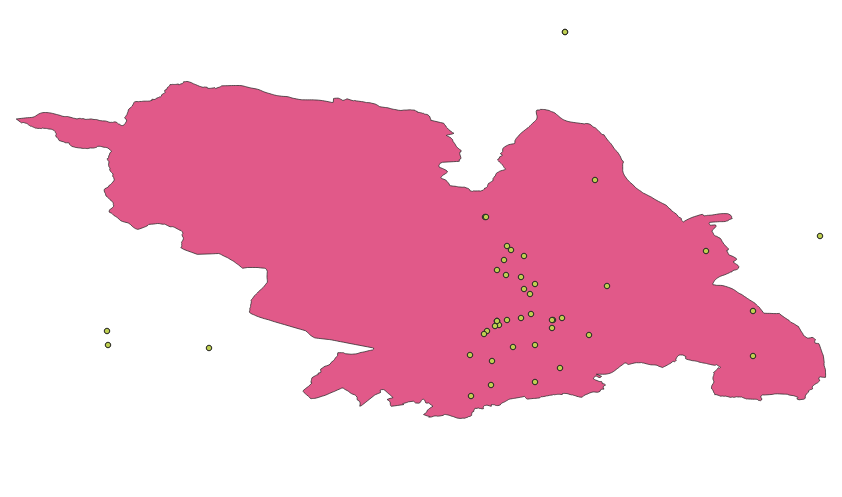
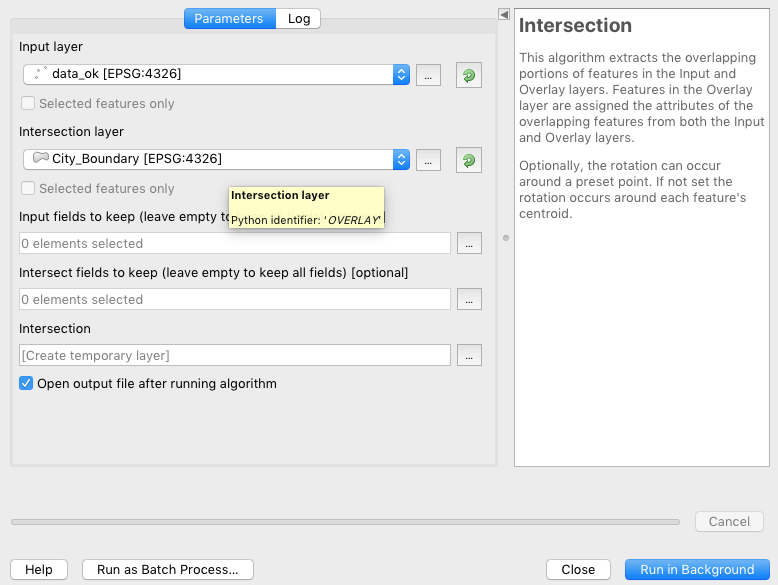
You can intersect the api data in a GIS software like QGiS to get the list of sensors in Sheffield.
Then you can use some script to download the data for these sensors. Examples in this forum.
Thank you for your reply. I am new to this so not sure how to work with the json data as I’ve never seen this before. How do I get the list of all the sensors I need using json?
Also is there a list somewhere for all the sensors in each region?
Hi, thank you so much for this step by step guide, I really appreciate it, I will give it a go. Once I have done the above, how would I use that information to download only the data for the specific sites? As I already have a list of the Sheffield sites but wasnt sure how to just download only their specific data
import requests
import time
#Mettre les ID des capteurs dans le tableau séparées par des virgules
#SDS11 only here
sensor_id = ["77136","77144","77445","33624","61705"]
#Mettre les dates dans le tableau au format 'YYYY-MM-DD' séparées par des virgules
dates = ["2022-01-01","2022-01-02","2022-01-03","2022-01-04","2022-01-05","2022-01-06","2022-01-07","2022-01-08","2022-01-09","2022-01-10","2022-01-11","2022-01-12","2022-01-13","2022-01-14","2022-01-15","2022-01-16","2022-01-17","2022-01-18","2022-01-19","2022-01-20","2022-01-21","2022-01-22"]
url_deb = 'http://archive.sensor.community/2022/'
for n1 in range(0,len(dates)):
date = dates[n1]
url_ok = url_deb + date
print(url_ok)
r1 = requests.get(url_ok)
source_code = r1.text
data_to_write ='sensor_id;sensor_type;location;lat;lon;timestamp;P1;durP1;ratioP1;P2;durP2;ratioP2\n'
for n2 in range(0,len(sensor_id)):
test = 'sensor_'+sensor_id[n2]+'.csv'
if test in source_code:
split1 = source_code.split(test)[0]
split2 = split1.split('<a href="')[-1]
url_fin = url_ok + '/' + split2 + test
print(url_fin)
r2 = requests.get(url_fin)
data = r2.text
split = data.splitlines(True)
#print(split)
for n3 in range(1,len(split)):
data_to_write += split[n3]
time.sleep(0.1)
f = open("/Users/PJ/Desktop/gressent/scrap_file_"+date+".csv", "a")
f.write(data_to_write)
f.close()